添加自定义积木
本文介绍如何创建一个自定义积木。
1. 如下图,打开添加自定义积木界面。
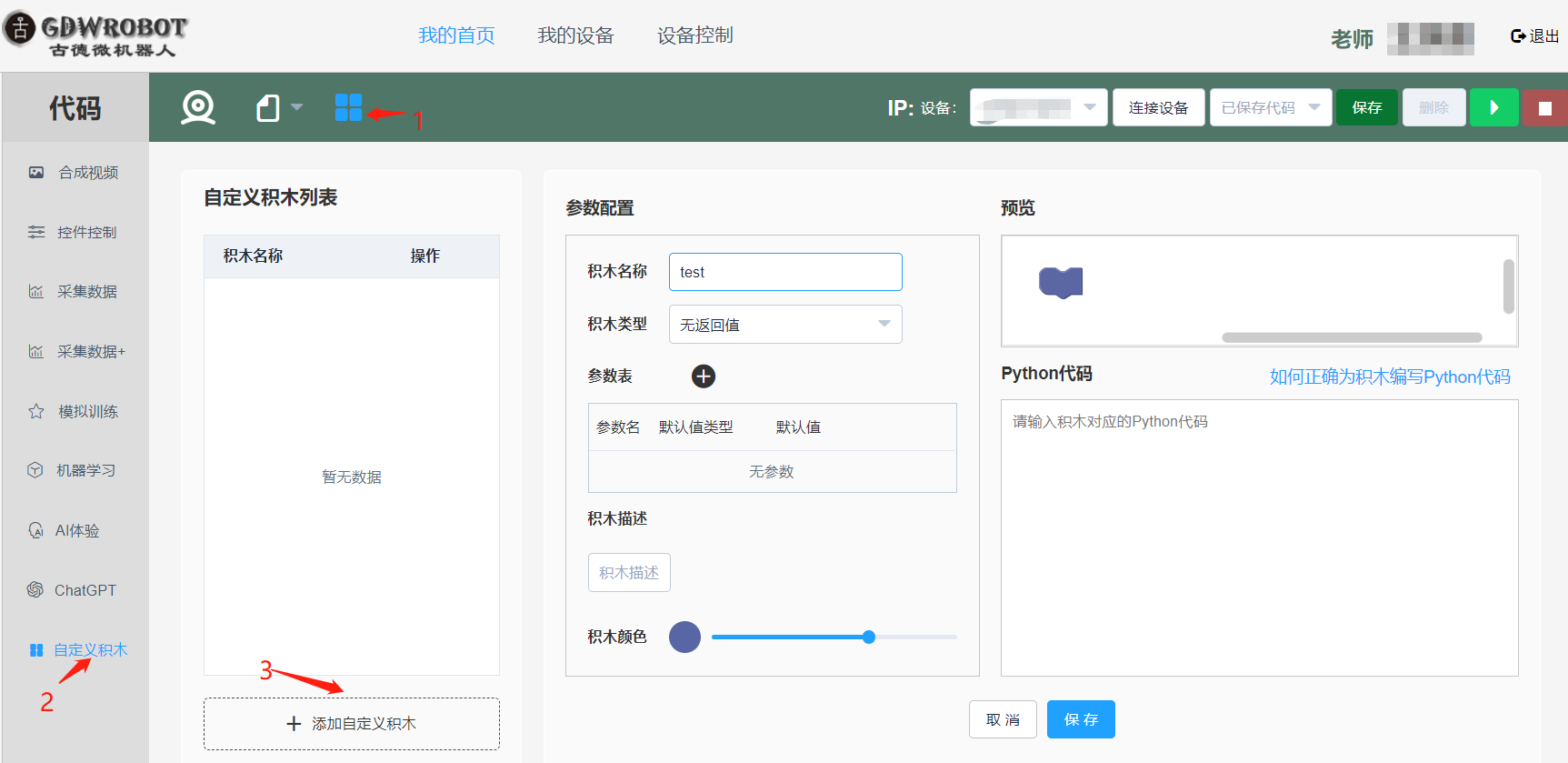
2. 如下图,配置积木参数,然后点击保存。
- 输入积木名称(必填)
- 选择积木类型,一共两种:有返回值和无返回值。
- 根据需要添加积木的参数。可以为参数设置默认值。
- 添加积木的文字描述
- 拖动滑动条设置积木颜色
- 积木预览区
- 给积木编写正确的Python代码。(如何编写见下文,这里可以先随便写一点代码)
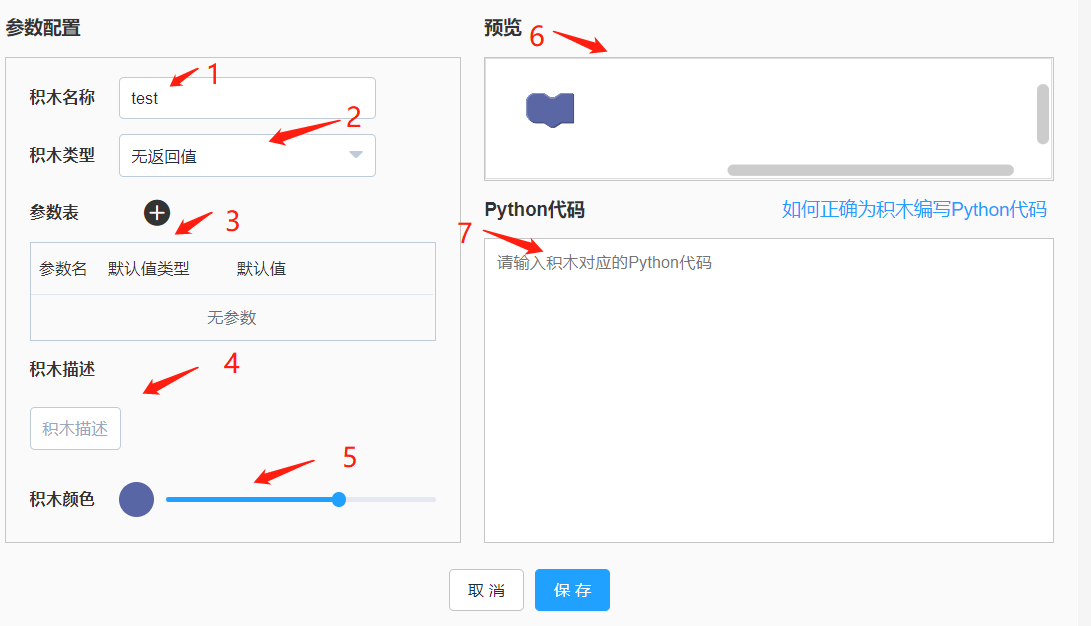
3. 返回代码编程页面,按F5刷新网页,然后在右侧积木导航栏最下面的自定义积木分类中即可看到刚才添加的积木。
4. 为自定义积木编写正确的Python代码
注意:Python是使用缩进来组织代码的,如果有多行代码需要组织,请仔细小心,不要出错。
4.1 为无返回值积木编写Python代码
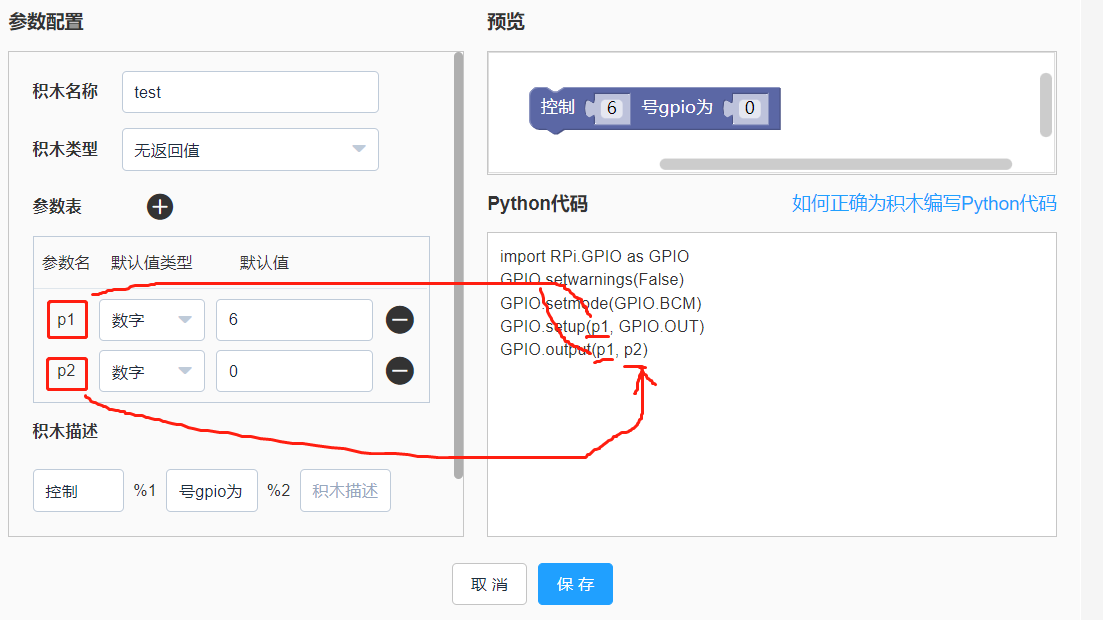
如下图的自定义积木有两个参数,参数名分别为p1和p2,想要在Python代码中使用积木中的这两个参数, 只要在需要的地方输入p1和p2即可。也支持一个积木对应多行代码。
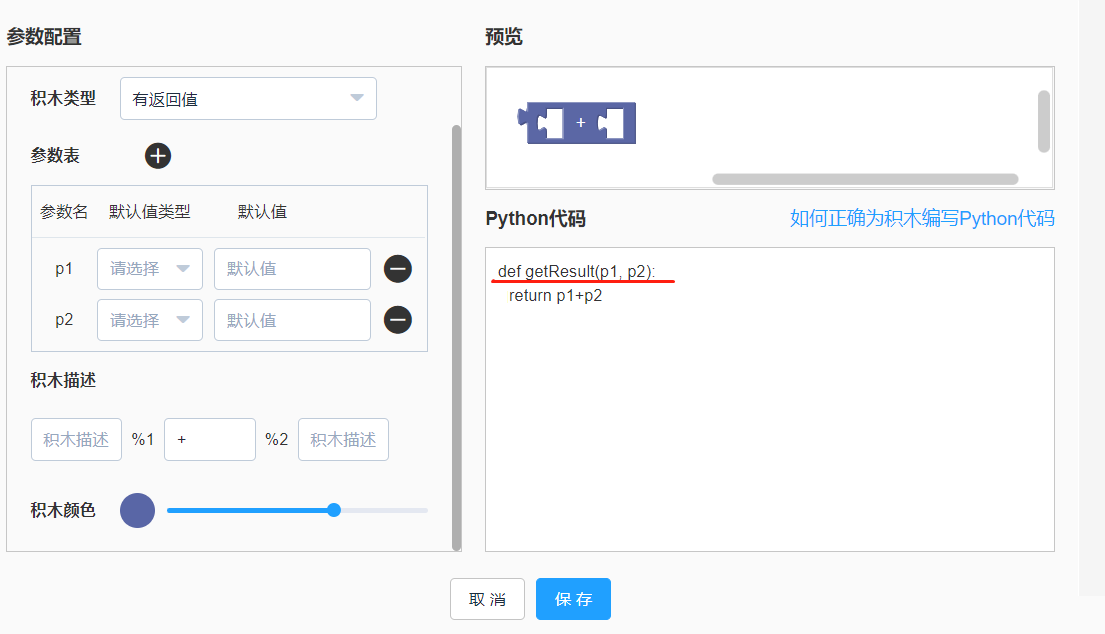
4.2 为有返回值积木编写Python代码
如下图,对于有返回值积木的Python代码,代码行数超过一行时,需要按照如下图的格式来写。
- 需要定义一个函数,函数的入参为积木的参数名。
- 函数记得return返回值。
5. 几个案例
5.1 使用百度AI进行文字识别
首先需要获取accessToken。 我们先创建一个获取accessToken的自定义积木,输入参数为API Key和Secret Key。 如下图
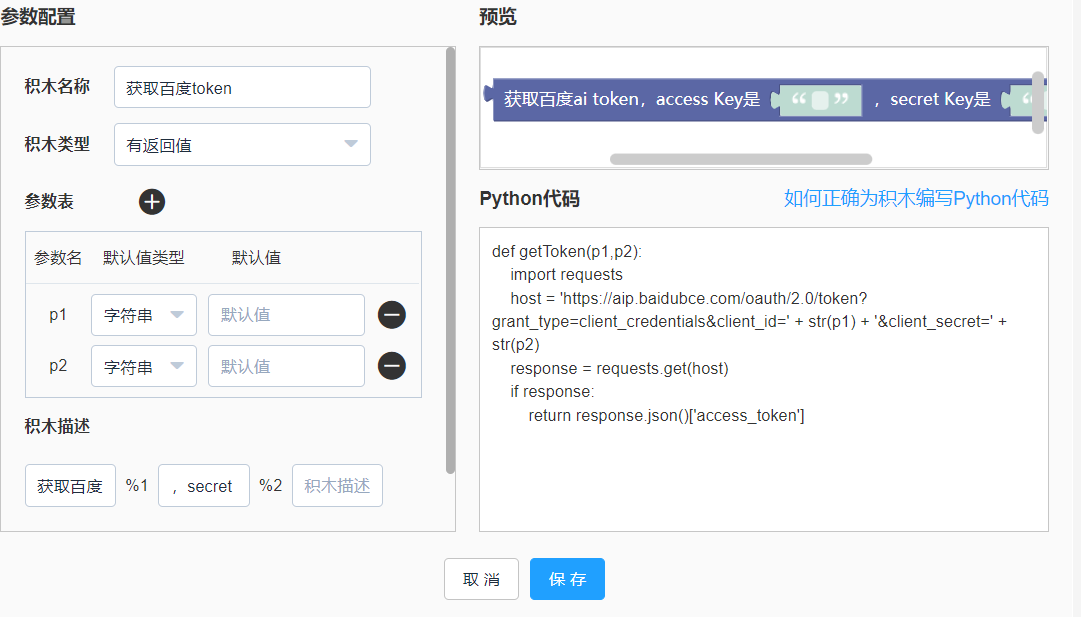
获取AccessToken的Python代码完整如下:
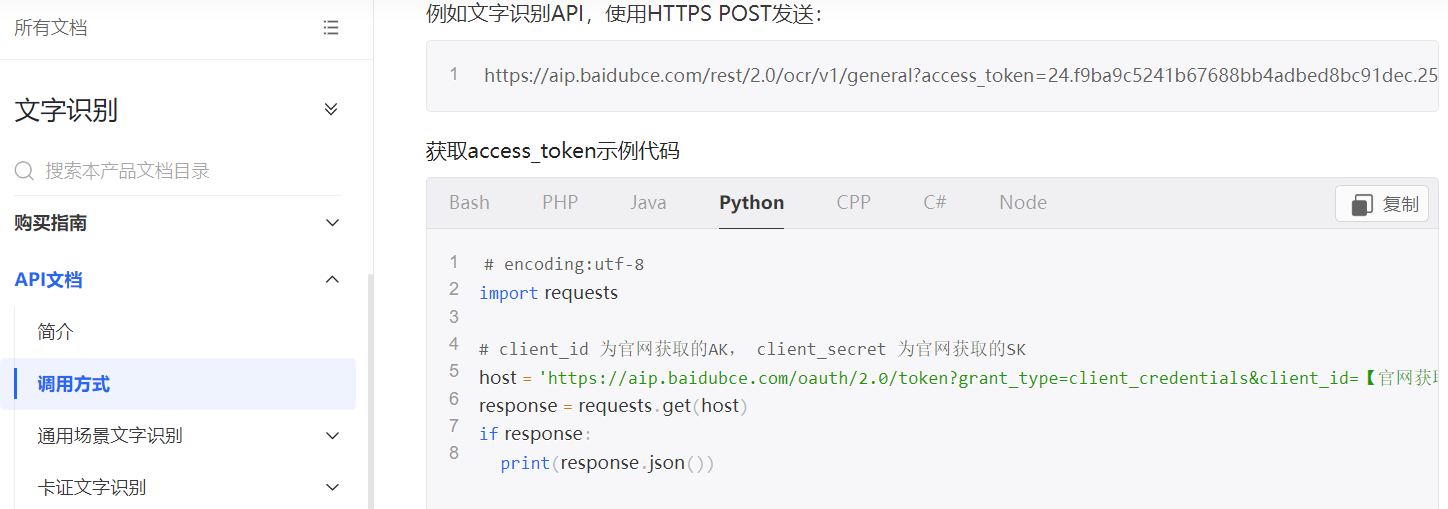
def getToken(p1,p2): import requests host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + str(p1) + '&client_secret=' + str(p2) response = requests.get(host) if response: return response.json()['access_token']这段获取百度AI token的代码是参考百度AI官方文档链接 (https://cloud.baidu.com/doc/OCR/s/Ck3h7y2ia) 中的样例代码来实现,样例代码如下图
然后使用百度AI的文字识别接口进行文字识别,需要两个参数,分别是AccessToken和图片的路径地址,创建自定义积木如下图
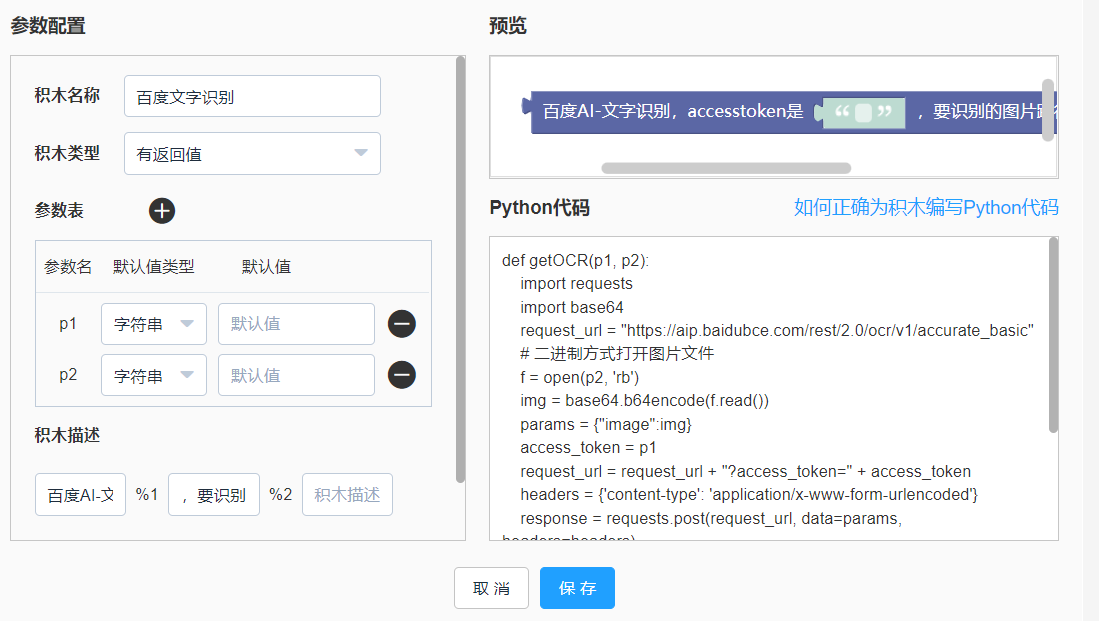
文字识别的Python代码完整如下:
def getOCR(p1, p2): import requests import base64 request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # 二进制方式打开图片文件 f = open(p2, 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = p1 request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) ret = '' if response: words_result = response.json()['words_result'] for word in words_result: ret += word['words'] return ret这段文字识别的代码是参考百度AI官方文档链接 (https://cloud.baidu.com/doc/OCR/s/1k3h7y3db) 中的样例代码来实现的,样例代码如下图:
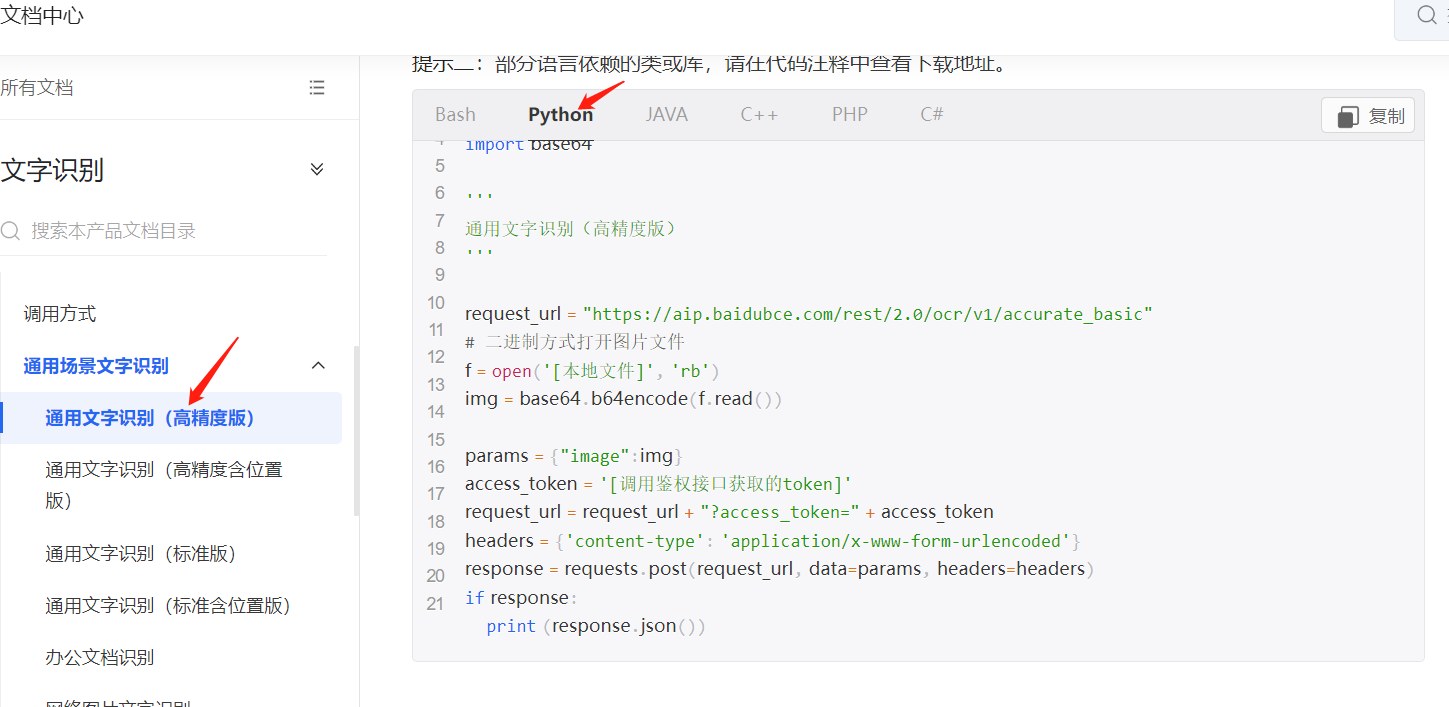
最后就可以用这两个自定义积木进行文字识别了。如下图

5.2 使用讯飞AI进行声纹识别
- 准备工作:
- 首先需要注册一个科大讯飞的账号。(如何注册就不多说了~~)
- 在控制台创建一个应用,如下图:

- 在控制台创建一个应用,如下图:
- 如下图,在控制台左侧的侧边栏找到【语音扩展】里的【声纹识别】,点击进入,就可以看到声纹识别的APPID, APIKey,APISecret,声纹识别API等信息(这些信息在下面的编程中都有用到)。
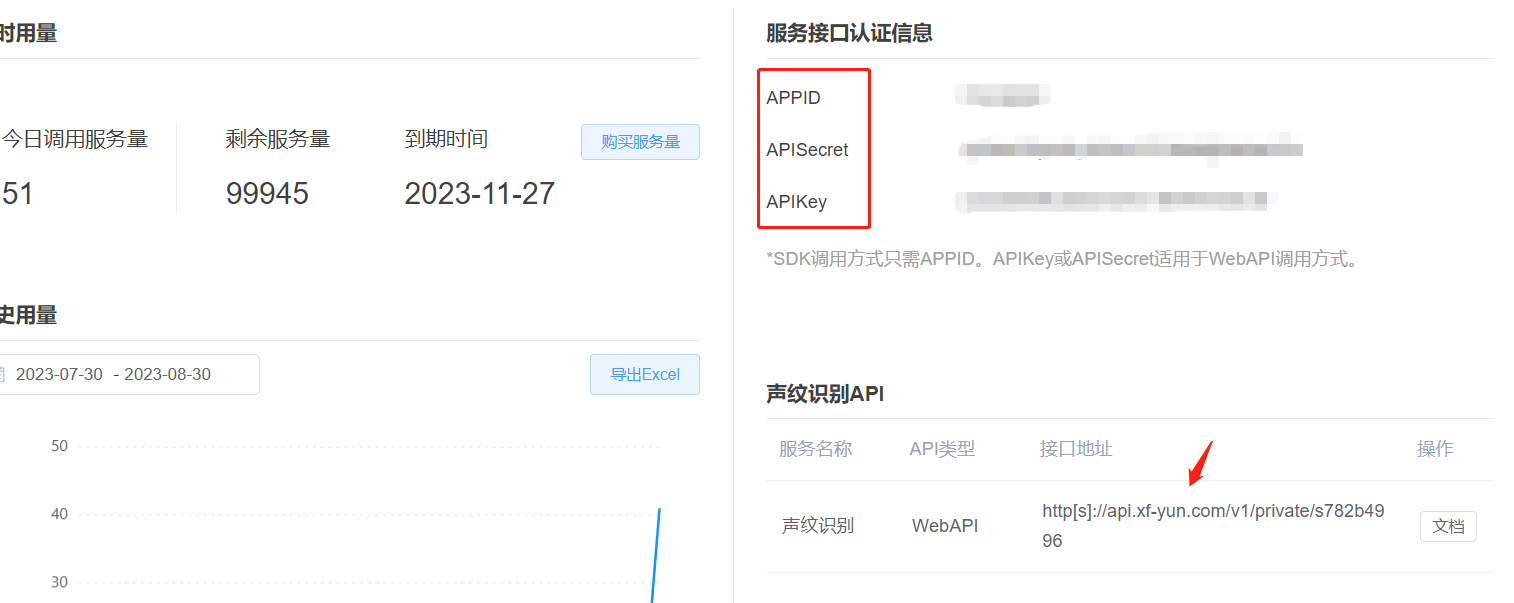
- 如下图,在控制台左侧的侧边栏找到【语音扩展】里的【声纹识别】,点击进入,就可以看到声纹识别的APPID, APIKey,APISecret,声纹识别API等信息(这些信息在下面的编程中都有用到)。
官方参考文档地址 (https://www.xfyun.cn/doc/voiceservice/isv/API.html)。
官方提供的Python Demo在如下图位置:
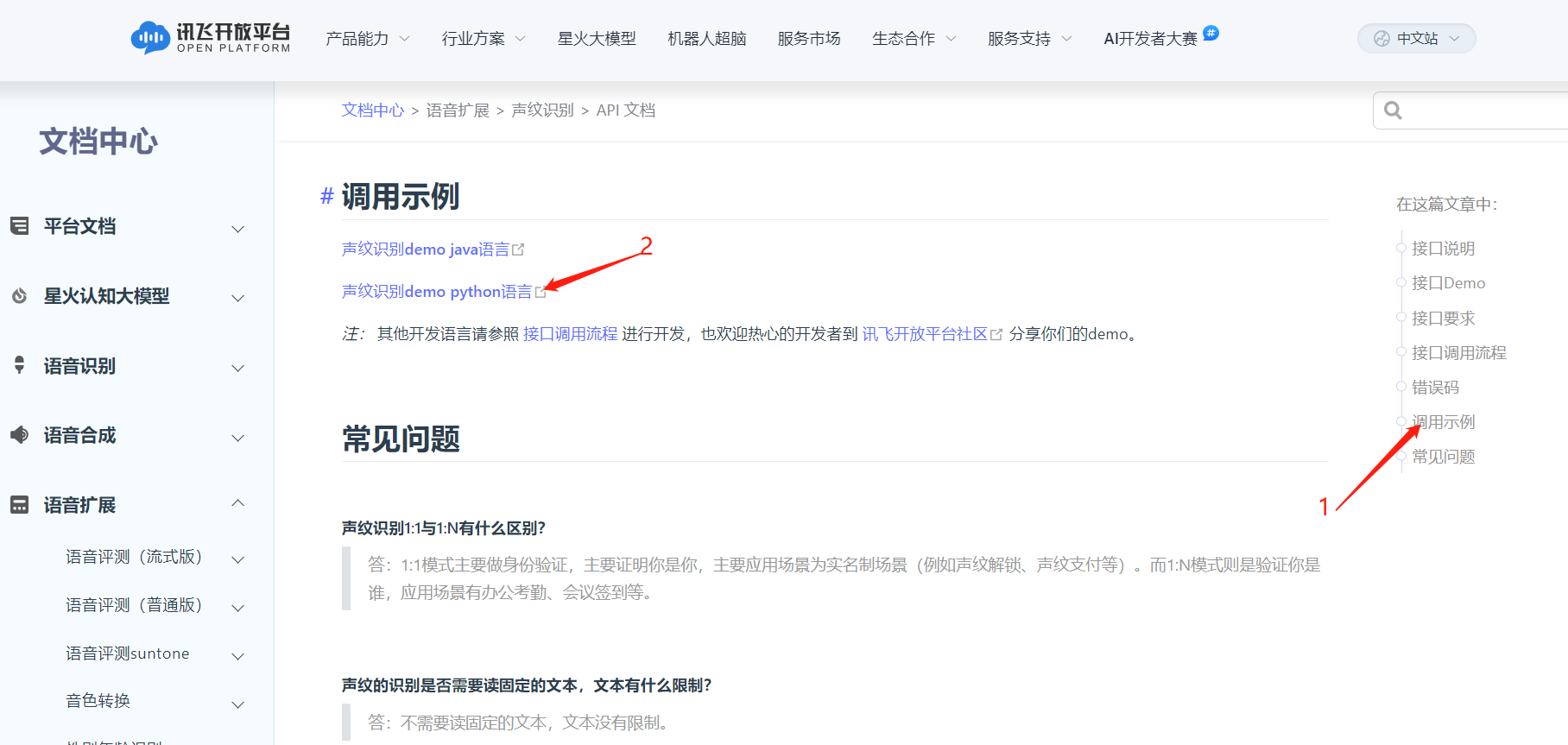
下面封装实现的python代码均基于官方Demo实现。
进行声纹识别主要由如下几个步骤:
- 创建声纹特征库(必须)
- 添加声纹特征(必须)
- 特征比对(必须)
- 查询特征列表(非必须)
- 删除制定特征(非必须)
- 删除声纹特征库(非必须)
- 注意:每次请求都需要携带一个签名,签名由url、APISecret、APIKey、date组成。由于跟时间相关, 每次请求都需要重新计算签名,因此封装的积木python代码前半段都是一样的,都是在计算签名。
创建声纹特征库积木,输入参数为声纹特征库ID (为字符串,支持字母数字下划线,长度最大为32)。 积木创建如下图:
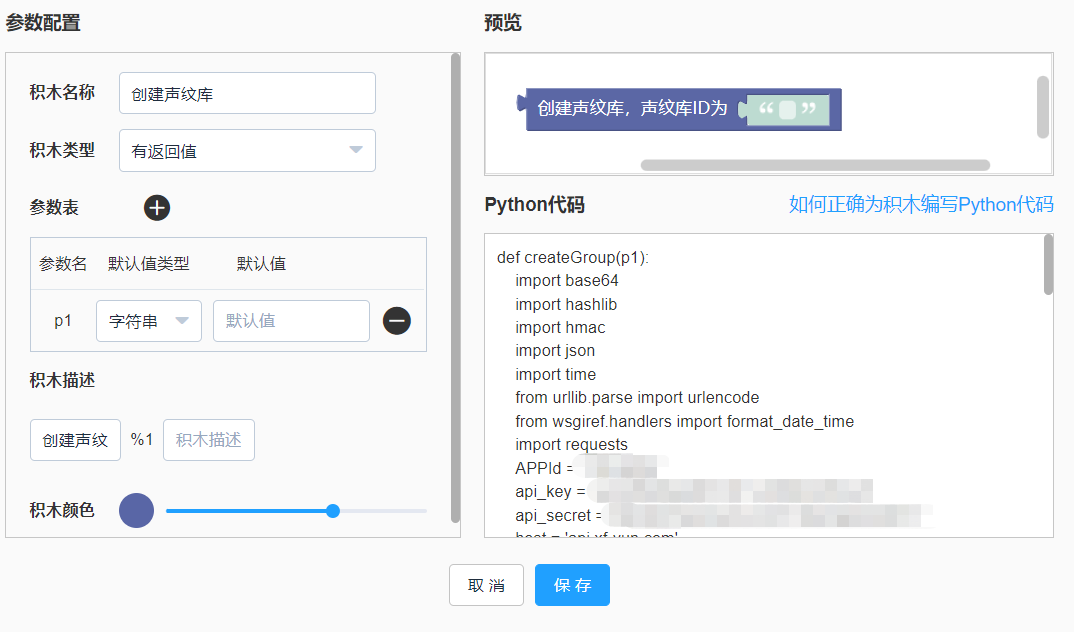
创建声纹特征库的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def createGroup(p1): import base64 import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "createGroup", "groupId": str(p1), "groupName": 'group_' + str(p1), "groupInfo": '', "createGroupRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: # return json.loads(base64.b64decode(tempResult['payload']['createGroupRes']['text']).decode('utf-8')) return '创建声纹库成功!' else: return tempResult['header']['message']
添加声纹特征积木,输入参数为声纹特征库ID、声纹特征ID、声纹特征描述、要添加的音频路径。
积木创建如下图:
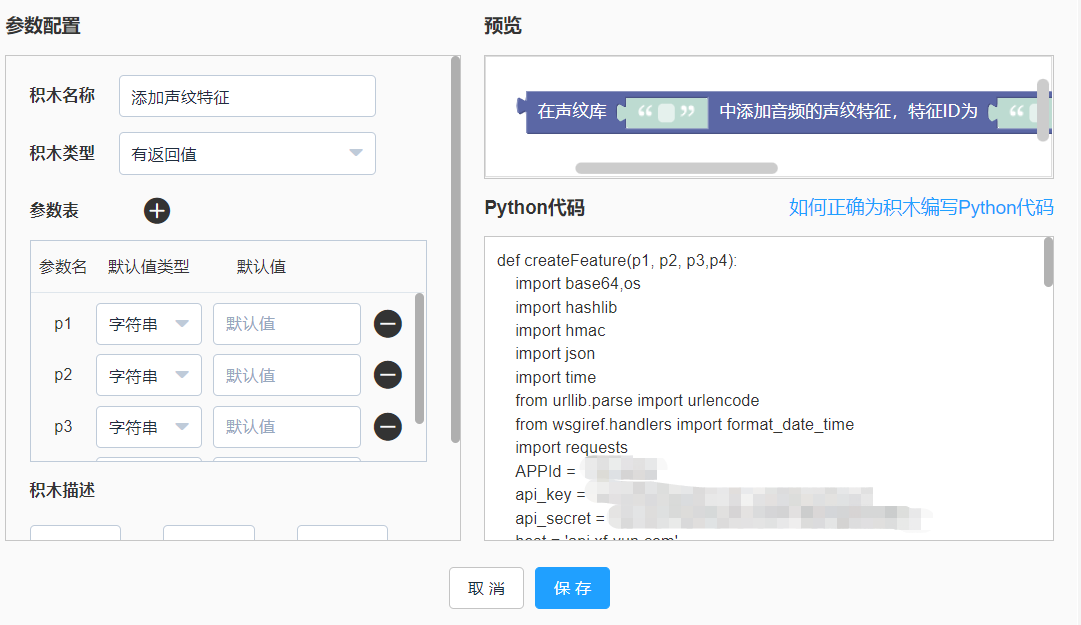
添加声纹特征的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def createFeature(p1, p2, p3,p4): import base64,os import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) newfile = str(int(time.time())) + '.mp3' os.system('ffmpeg -i %s -f mp3 %s' %(p4, newfile)) with open(newfile, "rb") as f: audioBytes = f.read() body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "createFeature", "groupId": p1, "featureId": p2, "featureInfo": p3, "createFeatureRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } }, "payload": { "resource": { "encoding": "lame", "sample_rate": 16000, "channels": 1, "bit_depth": 16, "status": 3, "audio": str(base64.b64encode(audioBytes), 'UTF-8') } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: # return json.loads(base64.b64decode(tempResult['payload']['createGroupRes']['text']).decode('utf-8')) return '添加声纹特征成功' else: return tempResult['header']['message']声纹对比积木,输入参数为声纹特征库ID、要对比的音频路径。
积木创建如下图:
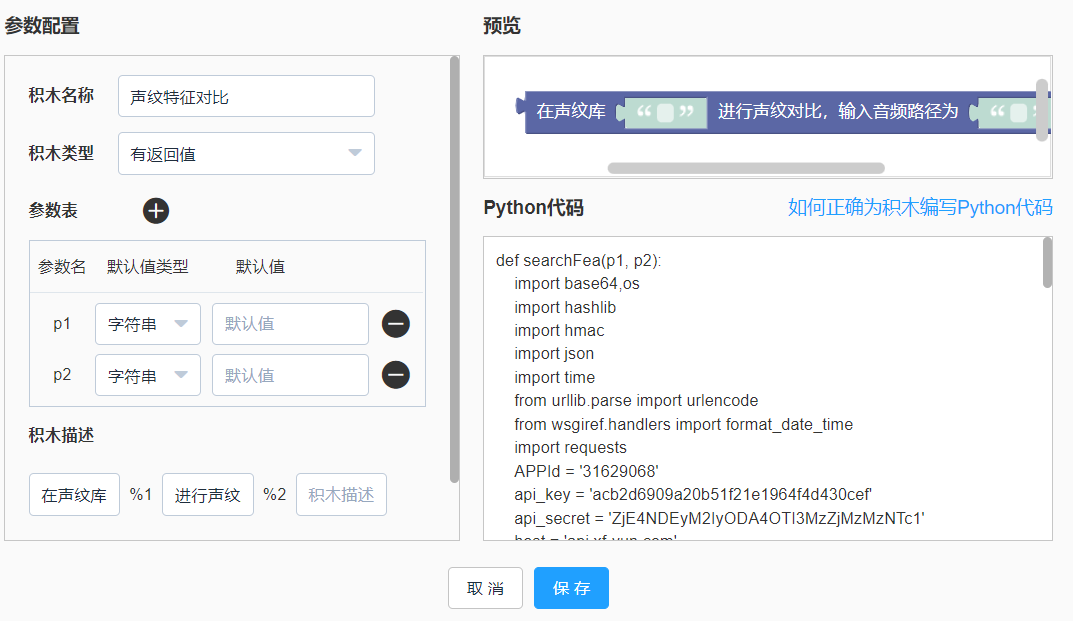
声纹对比的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def searchFea(p1, p2): import base64,os import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) newfile = str(time.time()) + '.mp3' os.system('ffmpeg -i %s -f mp3 %s' %(p2, newfile)) with open(newfile, "rb") as f: audioBytes = f.read() body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "searchFea", "groupId": p1, "topK": 1, "searchFeaRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } }, "payload": { "resource": { "encoding": "lame", "sample_rate": 16000, "channels": 1, "bit_depth": 16, "status": 3, "audio": str(base64.b64encode(audioBytes), 'UTF-8') } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: return json.loads(base64.b64decode(tempResult['payload']['searchFeaRes']['text']).decode('utf-8'))['scoreList'][0] else: return tempResult['header']['message']查询声纹特征积木,输入参数为声纹特征库ID。 积木创建如下图:
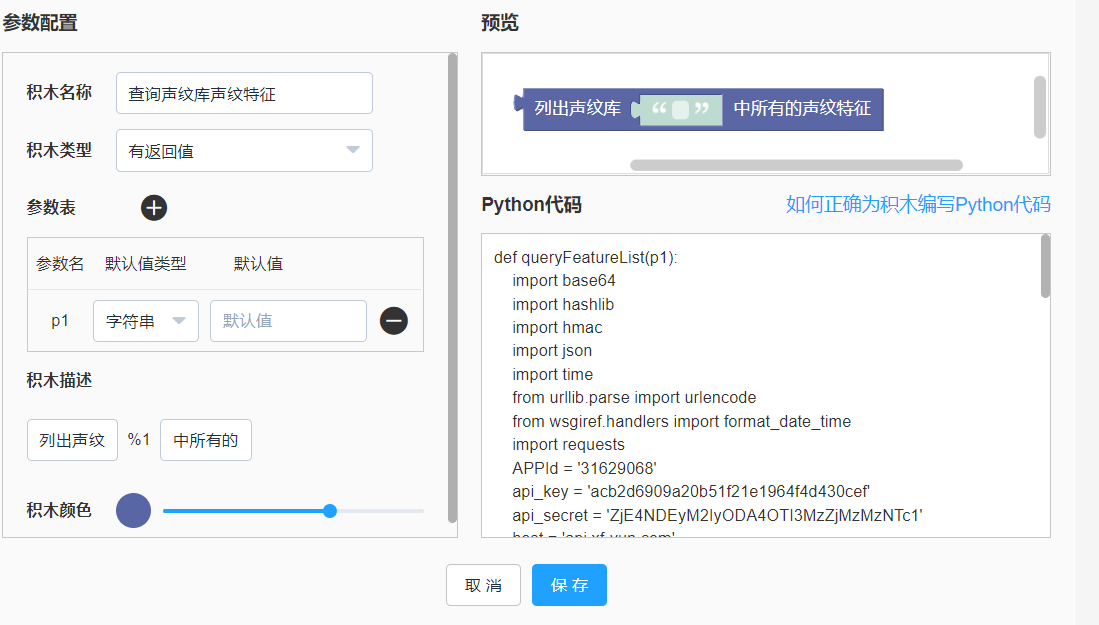
查询声纹特征的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def queryFeatureList(p1): import base64 import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "queryFeatureList", "groupId": p1, "queryFeatureListRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: return json.loads(base64.b64decode(tempResult['payload']['queryFeatureListRes']['text']).decode('utf-8')) else: return tempResult['header']['message']删除声纹特征积木,输入参数为声纹特征库ID、要删除的声纹特征ID。
积木创建如下图:
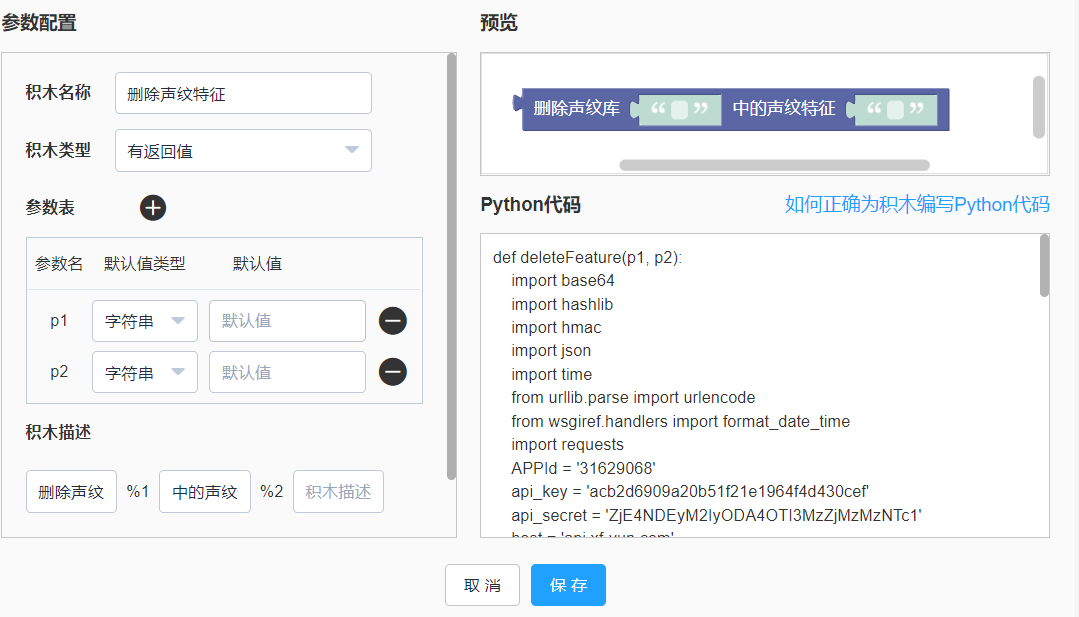
删除声纹特征的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def deleteFeature(p1, p2): import base64 import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "deleteFeature", "groupId": p1, "featureId": p2, "deleteFeatureRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: return '删除声纹特征成功!' else: return tempResult['header']['message']删除声纹特征库积木,输入参数为要删除的声纹特征库ID。
积木创建如下图:
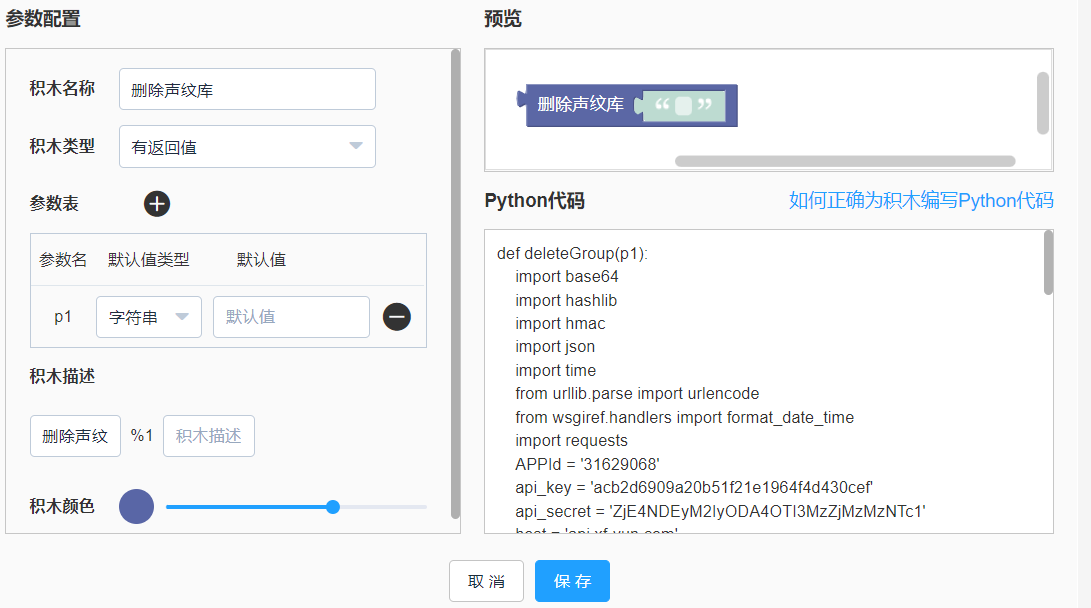
删除声纹特征库的Python代码完整如下:(注意替换成自己的APPID, APIKey,APISecret)
def deleteGroup(p1): import base64 import hashlib import hmac import json import time from urllib.parse import urlencode from wsgiref.handlers import format_date_time import requests APPId = '替换为自己的APPID' api_key = '替换为己的apikey' api_secret = '替换为自己的secret' host = 'api.xf-yun.com' path = '/v1/private/s782b4996' date = format_date_time(time.time()) signature_origin = "host: {}\ndate: {}\nPOST {} HTTP/1.1".format(host, date, path) signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (api_key, "hmac-sha256", "host date request-line", signature_sha) authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') values = { "host": host, "date": date, "authorization": authorization } request_url = 'https://' + host + path + "?" + urlencode(values) body = { "header": { "app_id": APPId, "status": 3 }, "parameter": { "s782b4996": { "func": "deleteGroup", "groupId": p1, "deleteGroupRes": { "encoding": "utf8", "compress": "raw", "format": "json" } } } } headers = {'content-type': "application/json", 'host': 'api.xf-yun.com', 'appid': '$APPID'} response = requests.post(request_url, data=json.dumps(body), headers=headers) tempResult = json.loads(response.content.decode('utf-8')) if tempResult['header']['code'] == 0: return '删除声纹库成功!' else: return tempResult['header']['message']最后用这上面的自定义积木实现一个简单的声纹识别的小案例。
首先创建声纹特征库。如下图

然后录制两段不同的声音,一段是我自己的说话声,一段是拍手的声音。我录制了10秒。如下图:


然后将这两段声音添加到声纹库中,创建两个不同的声纹特征,如下图:


然后就可以进行声纹特征对比了。

正常情况下,会返回一个字典,内容是置信度最高的声纹特征ID及其置信度等。根据讯飞的官方文档,一般置信度在0.6-1可以判定通过

测试发现,当声音很小时,会报错,返回
the audio data is invalid的错误提示。